Improving Quality
The individual effect of each proposed change in LAOM, our modification of LAPO, which overall improves latent action quality in the presence of distractors by 8x, almost closing the gap with distractor-free setting.
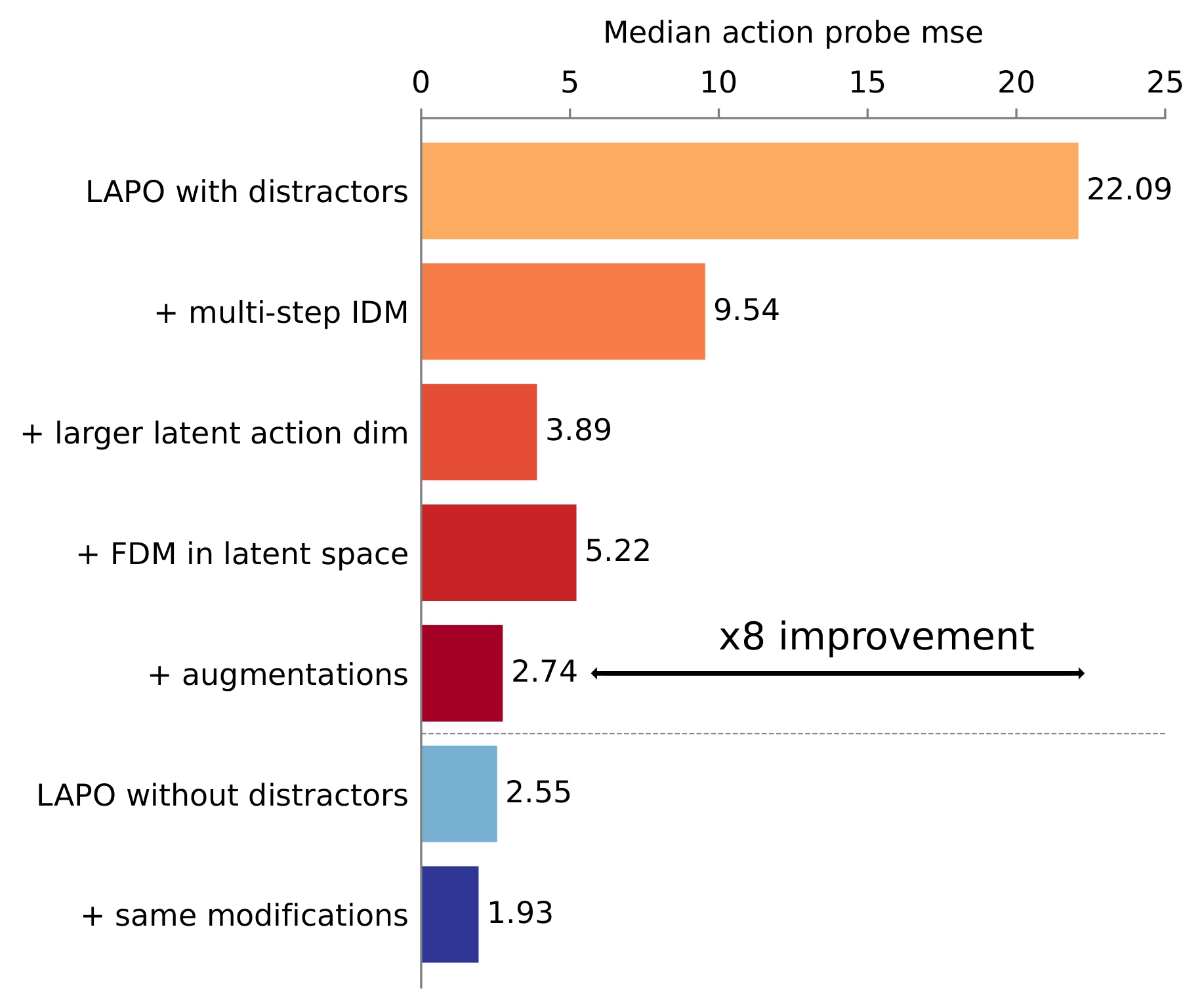
Despite the great promise, existing latent action learning approaches use distractor-free data, where changes between observations are primarily explained by real actions. Unfortunately, real-world videos encompass many activities that are unrelated to the task and cannot be controlled by the agent. We study how action-correlated distractors (dynamic backgrounds, camera shake, color changes, etc) affect latent action learning and show that:
The individual effect of each proposed change in LAOM, our modification of LAPO, which overall improves latent action quality in the presence of distractors by 8x, almost closing the gap with distractor-free setting.
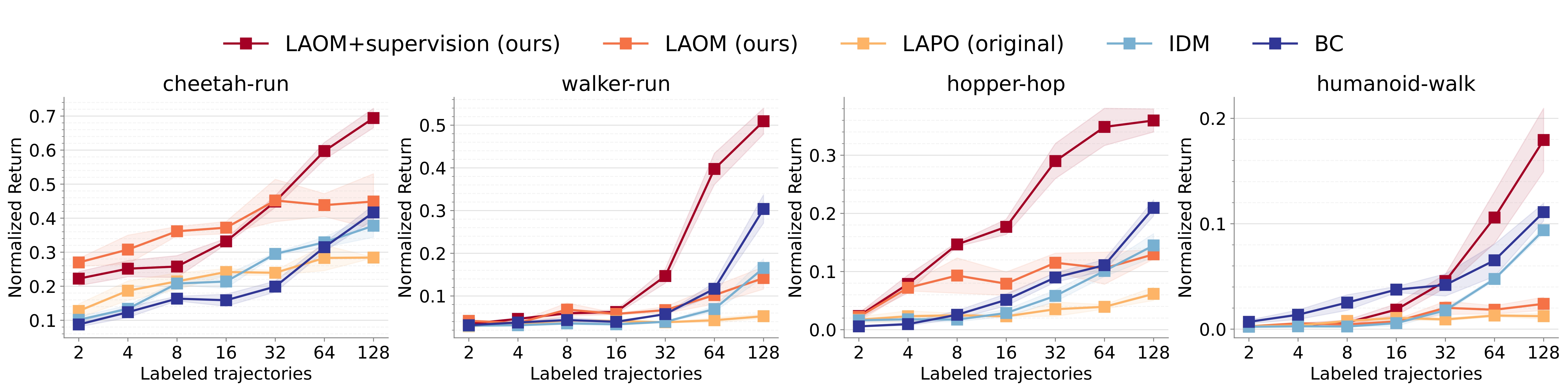
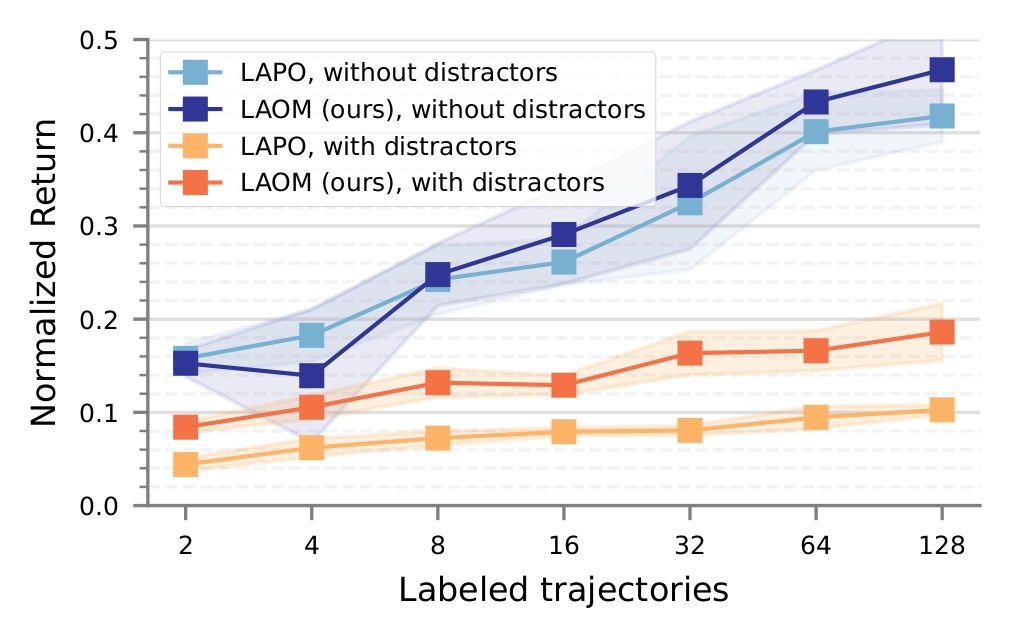
Our improvements partially transfer to downstream performance, as LAOM outperforms vanilla LAPO, improving performance by up to 2x. However, there remains a large gap in final performance with and without distractors.
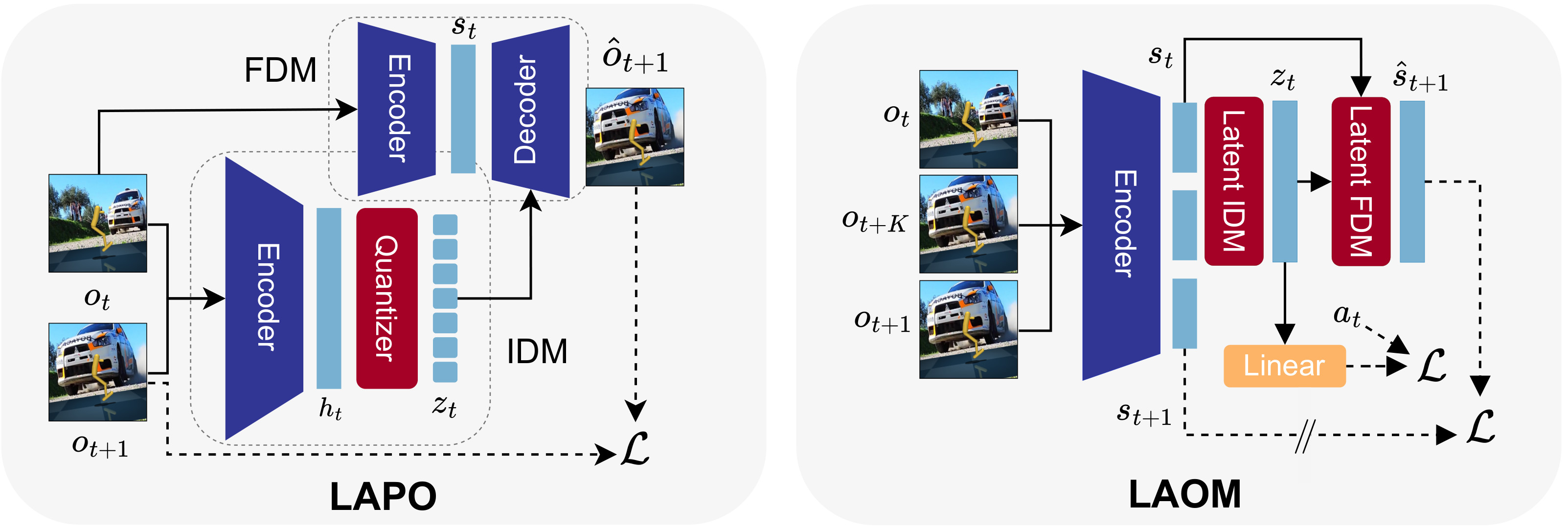
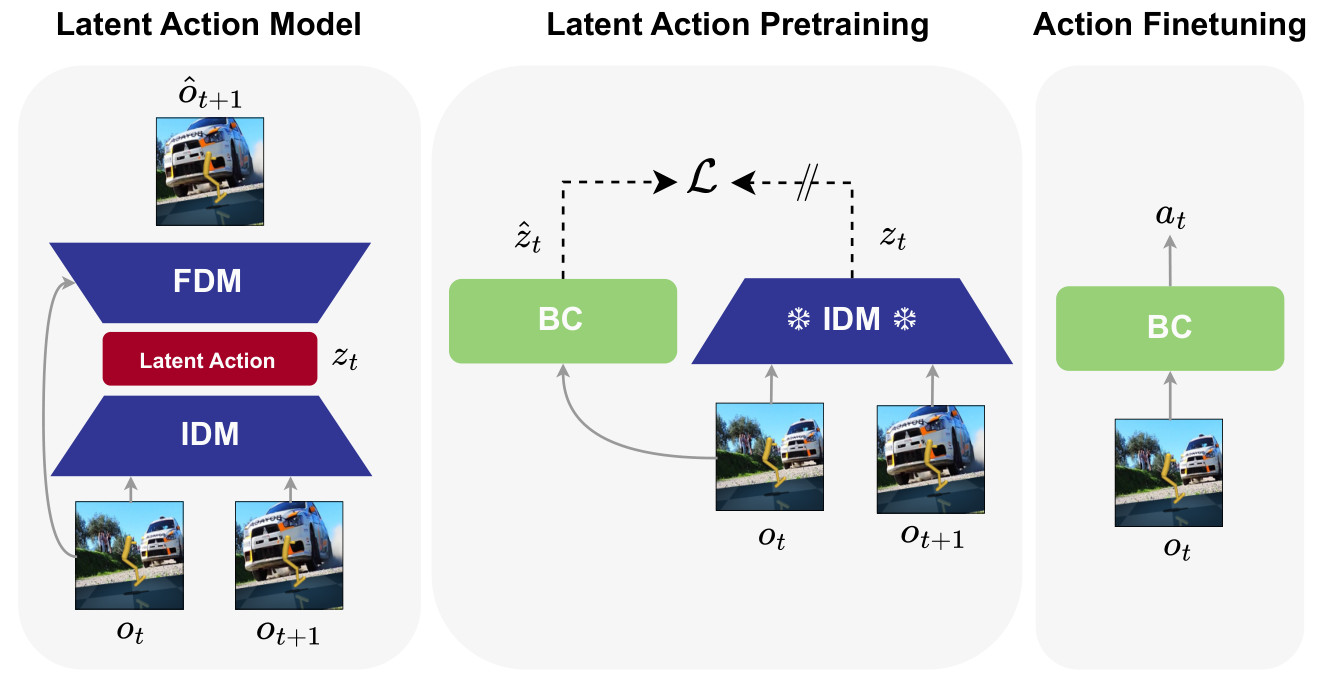
Simplified architecture visualization of LAPO, and LAOM - our proposed modification. LAPO consists of IDM and FMD, both with separate encoders, uses latent action quantization and predict next observation in image space. LAOM incorporates multi-step IDM, removes quantization and does not reconstruct images, relying on latent temporal consistency loss. Images are encoded by shared encoder, while IDM and FDM operate in compact latent space. When small number of ground-truth action labels is available, we use them for supervision, linearly predicting from latent actions.
Latent Action Model (LAM) is pre-trained to infer latent actions. It is then used to relabel the entire dataset with latent actions, which are subsequently used for behavioral cloning. Finally, a decoder is trained to map from latent to true actions. We do not modify this pipeline; we only examine the LAM architecture itself.
We collect datasets using Distracting Control Suite (DCS). DCS uses dynamic background videos, camera shaking and agent color change as distractors. We collect datasets with five thousand trajectories for four tasks.

@article{nikulin2025latent,
title={Latent Action Learning Requires Supervision in the Presence of Distractors},
author={Nikulin, Alexander and Zisman, Ilya and Tarasov, Denis and Lyubaykin, Nikita and Polubarov, Andrei and Kiselev, Igor and Kurenkov, Vladislav},
journal={arXiv preprint arXiv:2502.00379},
year={2025}
}